



敲黑板:關于 Kubernetes 架構,運維同仁一定要懂這些

打開這篇文章的同學,想必對 Docker 都不會陌生。Docker 是一種虛擬容器技術,它上手比較簡單,只需在宿主機上起一個 Docker Engine,然后就能愉快的玩耍了,如:拉鏡像、起容器、掛載數據、映射端口等等。相對于 Kubernetes(K8S)的上手,可謂簡單很多。
那么 K8S 是什么,又為什么上手難度大?K8S 是一個基于容器技術的分布式集群管理系統,是谷歌幾十年來大規模應用容器技術的經驗積累和升華的一個重要成果。所以為了能夠支持大規模的集群管理,它承載了很多的組件,而且分布式本身的復雜度就很高。又因為 K8S 是谷歌出品的,依賴了很多谷歌自己的鏡像,所以對于國內的同學環境搭建的難度又增加了一層。
下面,我們帶著問題,一步步來看 K8S 中到底有哪些東西?
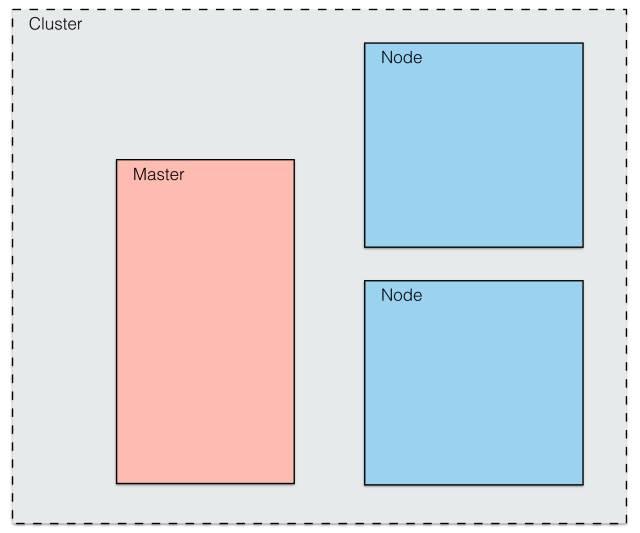
首先,既然是個分布式系統,那勢必有多個 Node 節點(物理主機或虛擬機),它們共同組成一個分布式集群,并且這些節點中會有一個 Master 節點,由它來統一管理 Node 節點。
如圖所示:
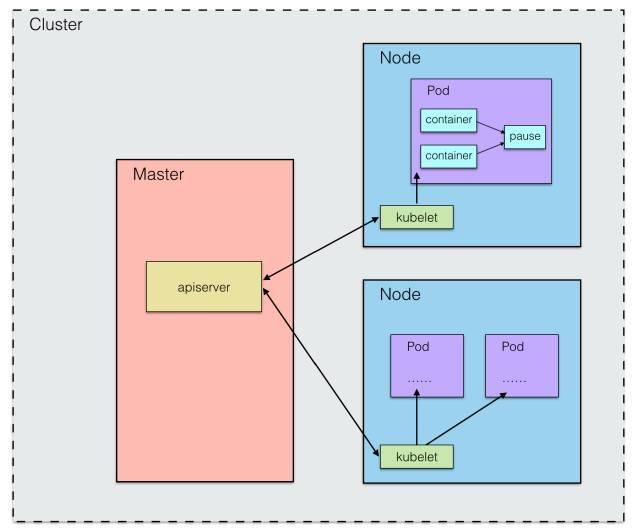
問題一:主節點和工作節點是如何通信的呢?
首先,Master 節點啟動時,會運行一個 kube-apiserver 進程,它提供了集群管理的 API 接口,是集群內各個功能模塊之間數據交互和通信的中心樞紐,并且它頁提供了完備的集群安全機制(后面還會講到)。
在 Node 節點上,使用 K8S 中的 kubelet 組件,在每個 Node 節點上都會運行一個 kubelet 進程,它負責向 Master 匯報自身節點的運行情況,如 Node 節點的注冊、終止、定時上報健康狀況等,以及接收 Master 發出的命令,創建相應 Pod。
在 K8S 中,Pod 是最基本的操作單元,它與 docker 的容器有略微的不同,因為 Pod 可能包含一個或多個容器(可以是 docker 容器),這些內部的容器是共享網絡資源的,即可以通過 localhost 進行相互訪問。
關于 Pod 內是如何做到網絡共享的,每個 Pod 啟動,內部都會啟動一個 pause 容器(google的一個鏡像),它使用默認的網絡模式,而其他容器的網絡都設置給它,以此來完成網絡的共享問題。
如圖所示:
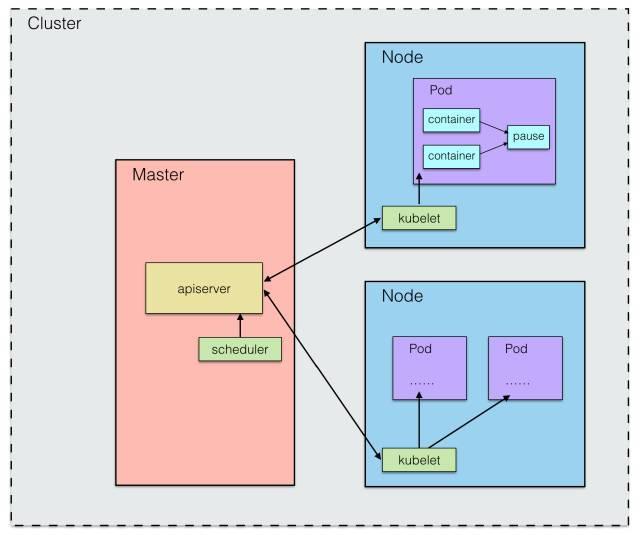
問題二:Master 是如何將 Pod 調度到指定的 Node 上的?
該工作由 kube-scheduler 來完成,整個調度過程通過執行一些列復雜的算法最終為每個 Pod 計算出一個最佳的目標 Node,該過程由 kube-scheduler 進程自動完成。常見的有輪詢調度(RR)。當然也有可能,我們需要將 Pod 調度到一個指定的 Node 上,我們可以通過節點的標簽(Label)和 Pod 的 nodeSelector 屬性的相互匹配,來達到指定的效果。
如圖所示:
關于標簽(Label)與選擇器(Selector)的概念,后面會進一步介紹
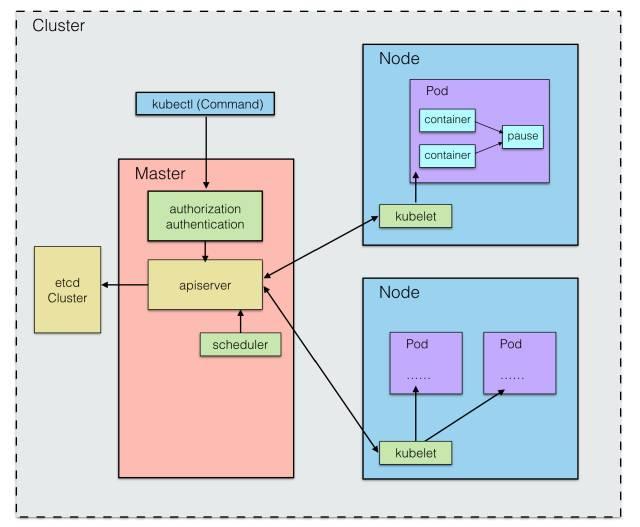
問題三:各節點、Pod 的信息都是統一維護在哪里的,由誰來維護?
從上面的 Pod 調度的角度看,我們得有一個存儲中心,用來存儲各節點資源使用情況、健康狀態、以及各 Pod 的基本信息等,這樣 Pod 的調度來能正常進行。
在 K8S 中,采用 etcd 組件 作為一個高可用強一致性的存儲倉庫,該組件可以內置在 K8S 中,也可以外部搭建供 K8S 使用。
集群上的所有配置信息都存儲在了 etcd,為了考慮各個組件的相對獨立,以及整體的維護性,對于這些存儲數據的增、刪、改、查,統一由 kube-apiserver 來進行調用,apiserver 也提供了 REST 的支持,不僅對各個內部組件提供服務外,還對集群外部用戶暴露服務。
外部用戶可以通過 REST 接口,或者 kubectl 命令行工具進行集群管理,其內在都是與 apiserver 進行通信。
如圖所示:
問題四:外部用戶如何訪問集群內運行的 Pod ?
前面講了外部用戶如何管理 K8S,而我們更關心的是內部運行的 Pod 如何對外訪問。使用過Docker 的同學應該知道,如果使用 bridge 模式,在容器創建時,都會分配一個虛擬 IP,該 IP 外部是沒法訪問到的,我們需要做一層端口映射,將容器內端口與宿主機端口進行映射綁定,這樣外部通過訪問宿主機的指定端口,就可以訪問到內部容器端口了。
那么,K8S 的外部訪問是否也是這樣實現的?答案是否定的,K8S 中情況要復雜一些。因為上面講的 Docker 是單機模式下的,而且一個容器對外就暴露一個服務。在分布式集群下,一個服務往往由多個 Application 提供,用來分擔訪問壓力,而且這些 Application 可能會分布在多個節點上,這樣又涉及到了跨主機的通信。
這里,K8S 引入了 Service 的概念,將多個相同的 Pod 包裝成一個完整的 service 對外提供服務,至于獲取到這些相同的 Pod,每個 Pod 啟動時都會設置 labels 屬性,在 Service 中我們通過選擇器 Selector,選擇具有相同 Name 標簽屬性的 Pod,作為整體服務,并將服務信息通過 Apiserver 存入 etcd 中,該工作由 Service Controller 來完成。同時,每個節點上會啟動一個 kube-proxy 進程,由它來負責服務地址到 Pod 地址的代理以及負載均衡等工作。
如圖所示:
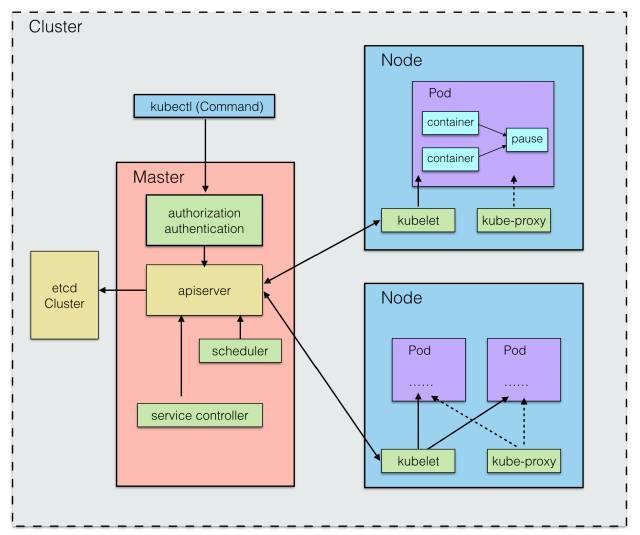
問題五:Pod 如何動態擴容和縮放?
既然知道了服務是由 Pod 組成的,那么服務的擴容也就意味著 Pod 的擴容。通俗點講,就是在需要時將 Pod 復制多份,在不需要后,將 Pod 縮減至指定份數。K8S 中通過 Replication Controller 來進行管理,為每個 Pod 設置一個期望的副本數,當實際副本數與期望不符時,就動態的進行數量調整,以達到期望值。期望數值可以由我們手動更新,或自動擴容代理來完成。
如圖所示:
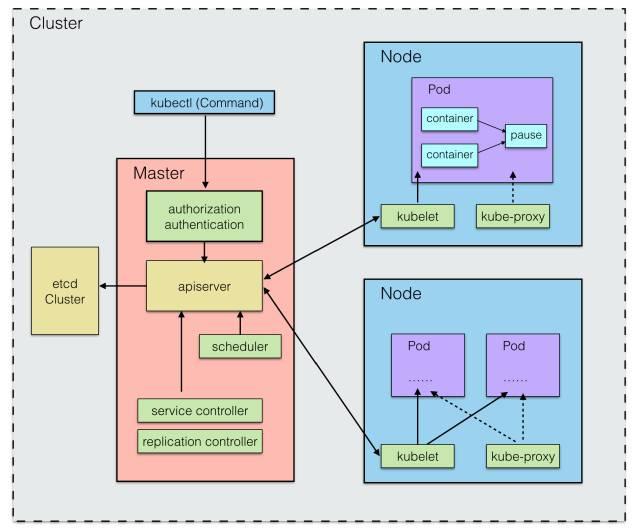
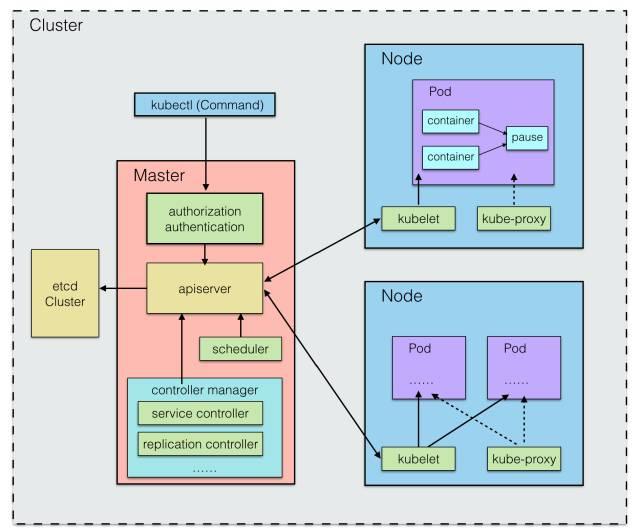
問題六:各個組件之間是如何相互協作的?
最后,講一下 kube-controller-manager 這個進程的作用。我們知道了 ectd 是作為集群數據的存儲中心, apiserver 是管理數據中心,作為其他進程與數據中心通信的橋梁。而 Service Controller、Replication Controller 這些統一交由 kube-controller-manager 來管理,kube-controller-manager 作為一個守護進程,每個 Controller 都是一個控制循環,通過 apiserver 監視集群的共享狀態,并嘗試將實際狀態與期望不符的進行改變。關于 Controller,manager 中還包含了 Node 節點控制器(Node Controller)、資源配額管控制器(ResourceQuota Controller)、命名空間控制器(Namespace Controller)等。
如圖所示:
總結
本文通過問答的方式,沒有涉及任何深入的實現細節,從整體的角度,概念性的介紹了 K8S 中涉及的基本概念,其中使用相關的包括有:
Node
Pod
Label
Selector
Replication Controller
Service Controller
ResourceQuota Controller
Namespace Controller
Node Controller
以及運行進程相關的有:
kube-apiserver
kube-controller-manager
kube-scheduler
kubelet
kube-proxy
pause
這也是我學習 K8S 后對其整體架構的一次總結,因為剛上手時,閱讀官方文檔,確實被如此多的內容搞得有點暈,所在在這里進行了簡單的梳理。文中有理解不到位的地方,歡迎指正!
企業級 Kubernetes 實踐沙龍專場現在免費贈票了!!
企業級 Kubernetes 實踐沙龍旨在分享交流 Kubernetes 的企業級整體實踐方案與案例,幫助您掌握實現容器云的核心技術。
上一篇:第一篇
下一篇: 「大數據」交通大數據平臺建設與運營方案
