



浪潮發布支持TensorFlow的FPGA計算加速引擎TF2
8月23日,在倫敦舉行的人工智能領域頂級會議KDD2018大會上,浪潮發布支持TensorFlow的FPGA計算加速引擎TF2,該產品可幫助AI客戶快速實現基于主流AI訓練軟件和深度神經網絡模型DNN的FPGA線上推理,并通過全球首創的FPGA上DNN的移位運算技術獲得AI應用的高性能和低延遲。

目前,采用FPGA技術實現AI應用的線上推理從而獲得可定制性、低延遲和高性能功耗比成為諸多AI公司采納的技術路線。但FPGA技術進入到大規模AI業務部署仍舊存在軟件編寫門檻高、性能優化受限、功耗難以控制等諸多挑戰。浪潮此次發布的TF2計算加速引擎的目標就是期望為客戶解決在AI應用FPGA技術的這些挑戰。

KDD18 浪潮展臺現場
TF2計算加速引擎由兩部分組成,第一部分是模型優化轉換工具TF2 Transform Kit,它將經過TensorFlow等框架訓練得到的深度神經網絡模型數據進行優化轉換處理,大幅降低模型數據文件大小,如它可將32位浮點模型數據壓縮為4位整型數據模型,使得實際模型數據文件大小精簡到原來的1/8,并基本保持原始模型數據的規則存儲;第二部分是FPGA智能運行引擎TF2 Runtime Engine,它可實現將前述已優化轉換的模型文件自動轉化為FPGA目標運行文件,為了消除深度神經網絡如CNN等對FPGA的DSP浮點計算能力的依賴,浪潮創新設計了移位運算技術,它可將32位浮點特征圖數據量化為8位整型數據,并結合前述4位整型模型數據,轉換卷積操作浮點乘法計算為8位整數移位運算,這將大幅提升FPGA做推理計算的性能并有效降低其實際運行功耗。這也是目前全球首次在基本保持原始模型計算精度的前提下在FPGA上實現深度神經網絡DNN的移位運算。
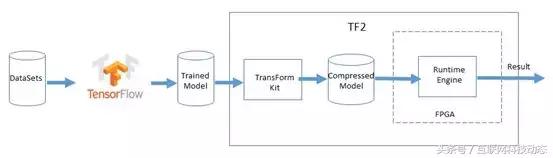
TF2計算加速流程
在浪潮F10A FPGA卡上采用SqueezeNet模型對TF2計算加速引擎進行的測試表現出了非常好的計算性能。F10A是全球首款支持Arria 10芯片的半高半長的 FPGA加速卡。SqueezeNet是一種典型的卷積神經網絡架構,模型精簡但其精度和AlexNet不相上下,特別適合于實時性要求較高的圖像類AI應用場景。在F10A上運行經過TF2引擎優化加速的SqueezeNet模型,在基本保持原始精度的情況下,單張圖片的計算耗時為0.674ms,在計算精度和延遲方面均略優于目前廣泛使用的GPU加速卡P4。
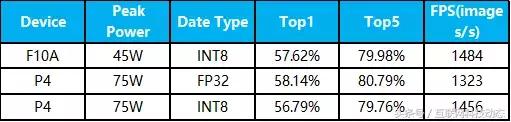
TF2 w/ F10A與GPU性能對比
浪潮TF2計算加速引擎通過移位運算、模型優化等技術創新,提高了FPGA上AI計算性能,降低了FPGA的AI軟件實現門檻,將支持FPGA廣泛應用于AI生態推動更多AI應用落地。浪潮計劃將TF2開放給其人工智能客戶,并將持續升級開發支持多種模型優化技術、最新深度神經網絡模型以及采用最新芯片的FPGA加速卡,預計新一代高性能FPGA加速卡的性能將是F10A的三倍左右。
浪潮是全球領先的AI計算力廠商,從計算平臺、管理套件、框架優化、應用加速等四個層次致力于打造敏捷、高效、優化的AI基礎設施。浪潮已成為百度、阿里和騰訊的最主要的AI服務器供應商,并與科大訊飛、商湯、曠視、今日頭條、滴滴等人工智能領先科技公司保持在系統與應用方面的深入緊密合作,幫助AI客戶在語音、圖像、視頻、搜索、網絡等方面取得數量級的應用性能提升。據IDC《2017年中國AI基礎架構市場調查報告》顯示,浪潮AI服務器市場份額達57%高居第一。
(文章來源:今日頭條)
上一篇:智慧城市建設,運營商能有啥優勢?
下一篇: 大數據+AI打造互聯網金融反欺詐體系
